GraphQL and FHIR
I know, some of these links won't work. Internal hub and all...but assume they were informative.
During I+P I spent some of my time looking at a FHIR to GraphQL plugin from The Guild (Envelop) to generically map various known schemas, including FHIR, to unopinionated GraphQL. e.g. a generic enough GraphQL schema that it can be done automatically instead of carefully traversing the source and target and agreeing on a mapping. Downside of being unopinionated: your GraphQL schema can be a little hard to navigate because it's not in the client's product/domain language and you're generally serving up your structure client side. Upside: with little effort you can stitch together / federate JSON, REST, FHIR, mySQL, oDate, gRPC, and more. Downside...if you're generalizing your GraphQL instead of carefully targeting the client's language /expectations/ease of use and instead of carefully mapping for where you get duplicate calls, you can lose a lot of the power / advantage that comes with GraphQL.
I have some familiarity with FHIR (Fast Healthcare Interoperability Resources) and Rasanjalee Dissanayaka M. Dissanayaka Mudiyanselage does an amazing, in-depth walkthrough here that puts my little bit of configuration programming to shame: Introduction to FHIR (Fast Healthcare Interoperability Resource). But I started at square one by reviewing the internally recommended Udemy (free) course, Introduction to FHIR. One hour long and I'd like to recommend you save yourself the hour and never watch it unless it's a requirement for your annual review I'll summarize it for you here:
Introduction to FHIR (1 hr) – Udemy - https://www.udemy.com/course/introduction-to-fhir/learn/lecture/11088132#overview by Vivian Sendling-Ortiz
Advice: I started by watching the opening parts on 1.25x (intro, JRE, Mirth install)…in retrospect, watch the whole thing on 1.25x or faster and be prepared to skip ahead. The presentation is primarily config and transform and a lot of waiting on installs/minor changes. Of interest, what is FHIR:
Fast Healthcare Interoperability Resources – an upgrade to HL7
HL7 2.x was basically unreadable – pipe separated sections
HL7 3.x was XML and a dismal failure
FHIR supports XML and JSON
All these versions and other specifications are out there and the mapping between them is generally already known.
What was important? Mirth (NextGen Connect) exists. It is a cross platform middleware interface engine for exchanging messages. A glorified transformation engine that understands the transforms between standards. Very anticlimactic.…I felt like I was back in my BizTalk days. However, Rasanjalee Dissanayaka M. Dissanayaka Mudiyanselage and I had a good discussion about Mirth because she did some of her own transform work for a POC (see the post above). So as a talking point, something to know, it's useful and moves you past simple - but potentially frequent - mapping to a dynamic process that gets a lot of table stakes transformation out of the way and gives you a place to codify one-off rules.
It's more fun to just play around with the installed Swagger
http://hapi.fhir.org/baseR4/swagger-ui/ - the OpenAPi/Swagger for experimenting with POST/GET against the API.
http://hapi.fhir.org/# - the base URL for HAPI FHIR. If you want to play the API, there's given and family and then there's name that does a match against both (Scott for instance) and returns a nice list that you can then use to examine the JSON and start to traverse the schema.
Here are some pictures of all that in action...but not the Mirth/NextGen Connect transformer. I recommend going over to Rasanjalee's post (Introd uction to FHIR (Fast Healthcare Interoperability Resource)) as she walks through all of this including inserts, updates, persistence layer, data structures, and more. What I call out below is a little- to no-code variation.
Grabbing a patient via gender...note this isn't part of the add-in, exactly (it is), we'll get to that...
A list that comes back from patient if I search on name = Scott (looking for matches in first || last)...
The response...
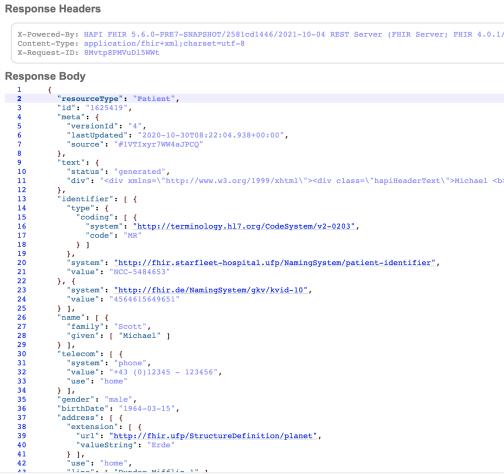
So WHAT does interrogating the FHIR online OpenAPI have to do with my dig into FHIR/GraphQL? Well, the add-in (you can grab the code here: https://gi thub.com/Urigo/graphql-mesh) is smart enough to allow you to simply point at that exact endpoint to consume the REST as a GraphQL structure. In a perfect world, you'd have your own FHIR server, but for demonstration purposes, pointing at a working demo on the web is at least a few magnitudes easier. Here's some of my YML pointed directly at that specification...in this case, the source is FHIR, but per above, there are add ins for other data sources as well and if you install them and map them in this yml, you can federate your GraphQL calls. I'll leave the concerns about performance for you to mull around in your head if you're doing multiple calls for a tree structure that reach to multiple locations for individual properties within a nested list.
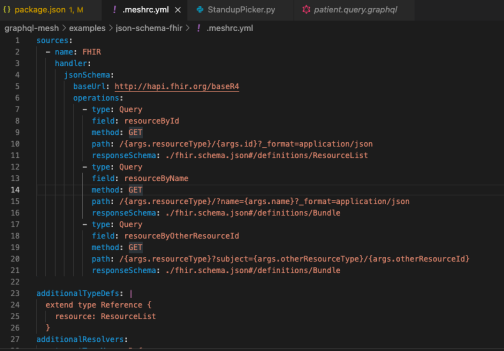
We'll get to the good part in a moment, but another important bit are the scripts to grab the schema and create/map/generate the unopinionated GraphQL schema from the latest FHIR version. Bonus....the addin serves up a local version of GraphiQL UI on localhost for you to play around with...don't worry about that error message in the terminal It's not important unless you think it is and the FHIR server is having simultaneous issues and you assume causation when it's just correlation. If you have the luxury, sometimes waiting is the best debugging.
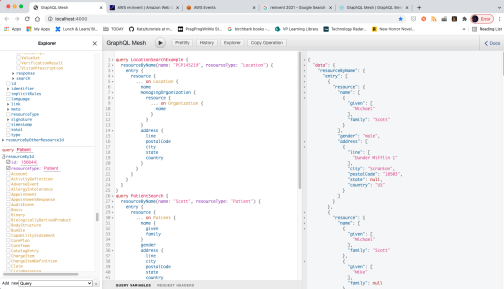
Head over to your browser. Change Jane to Scott (in my case), click/unclick any properties or sub-objects you want to add which automatically inserts them into the GraphQL JSON query (all conveniently saved as flat files with a graphql extension in example-queries), click the run button, and select the option you want (PatientSearch in this case) and voila...back come Scott records and all their data via GraphQL:
I know what you're thinking...Scott, you didn't code bupkis. Nothing. You installed Node, cloned Mesh from Github, ran the install for the connector, and ran the scripts that were laid out for you. Yep. And if you're lazier than I am you can even target the sandbox with files... https://codesandbox.io/s/github /Urigo/graphql-mesh/tree/master/examples/openapi-stackexchange?file=/package.json or the sandbox without files... https://9u5jz.sse.codesandbox.io/
So...what did I learn from my configuration adventure and why did I do it?
Uri told me to in "Let’s Build! FHIR + GraphQL Mesh – Connect All Your Existing Sources into One Data Graph with FHIR and GraphQL Mesh" (57:16) and I really wanted to see it for myself. It felt like he skipped some steps/parts because it was so easy and I wanted to know if that was realistic or if it was more complicated than he was letting on: https://www.youtube.com/watch?v=bnLB98xQc9o - https://www.youtube.com/watch? v=bnLB98xQc9o
The ability to federate multiple data sources with little to no effort (until you run into performance concerns) and map them all to a unified only what's-asked-for response is incredibly powerful.
It moves the exploration of the FHIR specification client side and modifications to that specification (via OpenAPI, limited / sub-version / hosting as a RDBMS structure) can be accommodated by regenerating the GraphQL schema (although keeping in mind rules around deprecating fields). I can interrogate the FHIR schema like it's JSON and see real results without many individual GETs.
GraphQL provides numerous advantages over the REST implementation with complicated/nested schemas:
Avoids overfetching (only the data asked for)
Full intent in one query/one result
Spec is typed
Can “explore” client side using GraphiQL (or other tools) and you don’t have to be a developer to explore the data/queries. There are Server/Client versions…you can incrementally expand/build out the schema as you expand/build your data source or handlers, and the schema isn't hidden in the code.
GraphQL Mesh builds on GraphQL advantages:
Uses existing services/standards/sources (SQL, GRPC, MQ, SOAP, OpenAPI/Swagger, oData, MSGraph, GraphQL….). And now, a FHIR handler (SOAP handler + JSON schema handler + some extra bits). They're looking for a good option / use case for a MS SQL handler.
Uses the original GraphQL protocol but with a better dev experience (e.g. the whole "non-opinionated" aspect versus learning a new data structure)
Run/execute anywhere
Federated: connections between different graphs (an example is an event, like a dev conference, with a city/location, and there’s a separate city service with weather…all events can be returned in a response that includes weather as a property or subobject for each event).
Already handles mutations and will be getting more support. FHIR is a big focus because Uri himself was consulting with companies going after easy FHIR implementations.
No comments:
Post a Comment